Adversarial Agents: How I Build AI Systems That Argue Before They Decide
A few years into building AI workflows for clients, I realized that most agentic AI systems being demoed online have the same problem. They are confident, they are coherent, and they are wrong in ways that are very hard to catch. One agent does the work, one agent reviews it, and the review agent agrees with the work agent, because they were trained on the same internet and they reach for the same conclusions.
That is not a system. That is a single agent in two costumes.
The systems I build do something different. They are structured so that the agents are forced to disagree. One agent makes the case. A second agent, with a different role, different temperature setting, and sometimes a different model entirely, is given the same data and instructed to build the strongest possible case against. A third agent presides. A human signs off. Nothing automated touches the final decision.
This is what I mean when I say I build adversarial agentic AI systems. And after running this pattern in production for over a year now in financial markets, I am convinced the same architecture solves operational problems in almost every industry where the cost of a confident wrong answer is meaningful.
This post is the long version of how it works, what it costs at the line item level, and where it is going next.
What an Adversarial Agent System Actually Is
Most people, when they hear "multi-agent," picture a swarm of bots dividing up work. That is one pattern. It is not the interesting one.
The interesting pattern is this. You take a high-stakes decision (a trade, a dispatch call, a regulatory interpretation, a maintenance deferral) and you architect the AI system so that the question is answered by a pipeline of specialists who do not see each other's reasoning until the appropriate moment. Each one is told to do their job and only their job. A bull advocate makes the bull case. A bear advocate makes the bear case. A judicial agent reads both and decides which case is stronger. A risk panel pressure-tests the surviving thesis from three different temperaments. A portfolio manager (the human in my case) signs the directive.
The reason this works has nothing to do with the models being smarter. It has to do with the architecture being honest about how decisions go wrong. Confident wrong answers happen when one perspective is allowed to frame the entire conversation. Adversarial architecture refuses to let that happen.
The other piece that matters: model selection by role. There is no reason every agent in the pipeline should be running the same model at the same temperature. A safety auditor should be running at temperature 0.1 with a model that is conservative and literal. A creative copywriting agent (in marketing workflows, not these) might run at 0.8 on a model tuned for fluency. A financial analyst sits somewhere in the middle. Picking the model and temperature per agent is not a detail. It is the engineering decision that separates a serious system from a demo.
TradingAgents: The Proof That the Pattern Works
The clearest example of this architecture running in production is TradingAgents.website, a platform I built and operate. It runs 16 named AI agents across three pipelines (equities, crypto, and prediction markets), pulls intelligence from 12 proprietary OSINT channels, and produces institutional-grade analysis with full audit trails.
The equity pipeline is the one most people start with. It has six stages.
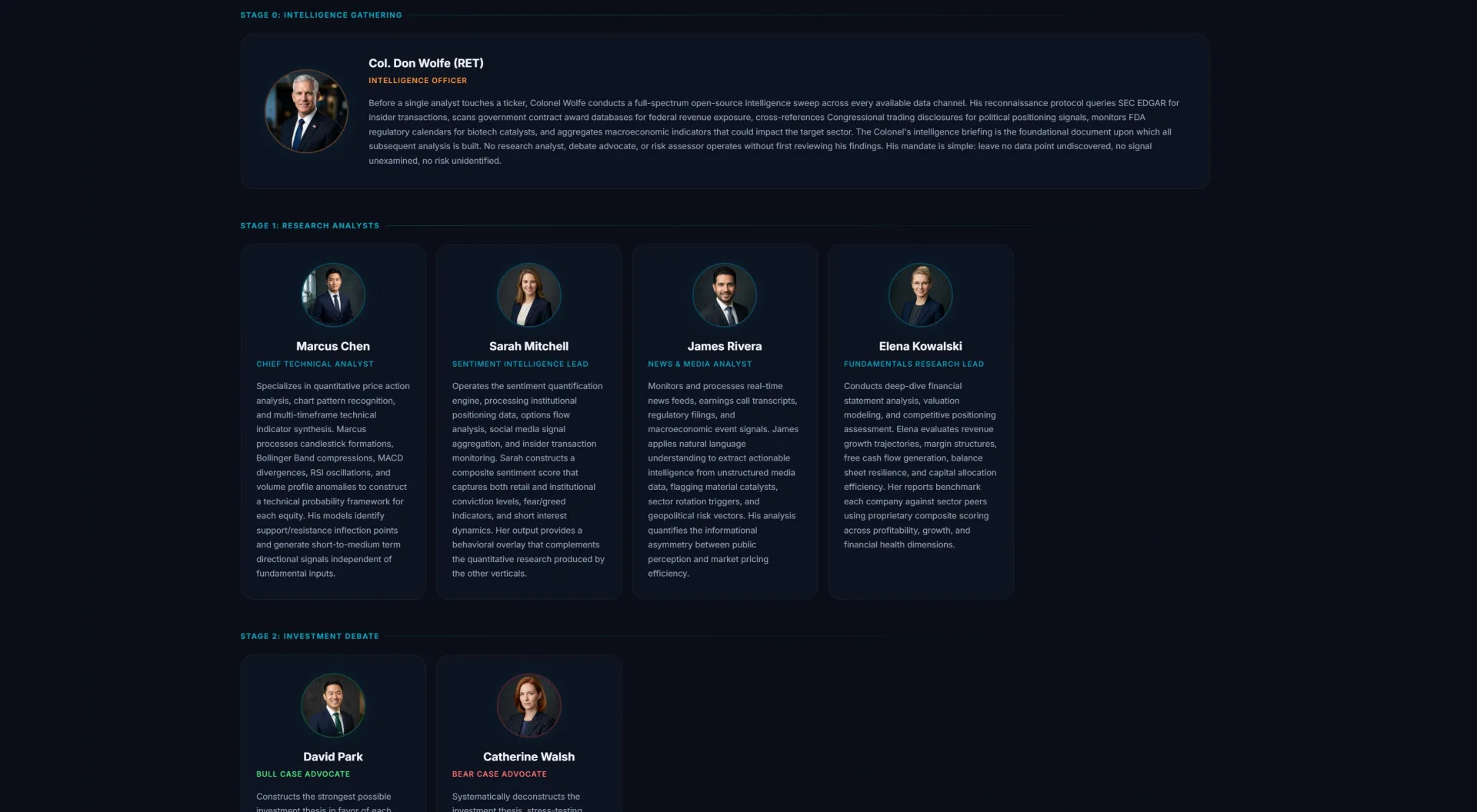
Stage 0 is intelligence gathering. An agent named Colonel Don Wolfe (yes, every agent has a name, because it is easier to say "Wolfe ran the sweep" than to reference a function call in conversation) executes a full-spectrum OSINT pass. SEC EDGAR for insider transactions. USASpending and federal contract awards for government revenue exposure. Congressional trading disclosures. FDA calendars for biotech catalysts. FRED for macro. Options flow. The output is a structured intelligence briefing that every downstream agent has to read before they are allowed to speak.
Stage 1 is research. Four analyst agents (Marcus Chen on technicals, Sarah Mitchell on sentiment, James Rivera on news and media, Elena Kowalski on fundamentals) independently process the briefing. They do not see each other's work. Zero cross-talk. This is deliberate. If they collaborated, they would converge. We do not want them to converge. We want four independent reads.
Stage 2 is the adversarial debate. David Park is the Bull Advocate. Catherine Walsh is the Bear Advocate. They are given identical data and told they may not equivocate. David's job is to build the strongest possible case for accumulation. Catherine's job is to systematically dismantle that case. The output is not a recommendation. It is two opposing theses constructed at full strength.
Stage 3 is the verdict. Michael Torres, the Research Director, reads both arguments and renders a judicial assessment of which one is more defensible. He has no predetermined bias. His job is to evaluate evidence quality, logical consistency, and analytical rigor. Whichever thesis survives becomes the foundation for the next stage.
Stage 4 is the risk panel. Three risk analysts examine the surviving thesis through aggressive, conservative, and neutral lenses. A Risk Judge synthesizes their inputs into a unified verdict.
Stage 5 is portfolio consensus. This is where I, the human, sit. I review the full record (every agent's reasoning, every debate argument, every risk assessment) and make the final call. Position sizing, entry timing, whether to act at all. Nothing executes automatically. Every decision is human-in-the-loop by design.

That is one pipeline. There are two more.
The Polymarket pipeline runs six agents purpose-built for binary prediction markets. Nadia Petrova gathers event intelligence. Lena Torres argues YES. Ryan Ashford argues NO. Derek Harmon, a contrarian, stress-tests both sides for cognitive bias, base rate neglect, and groupthink. Dr. Anika Patel synthesizes a Bayesian probability. Marco Chen compares the AI's probability against the live market price and calculates the edge. If the AI says 62% and the market is priced at 48%, Marco flags it as a mispriced contract worth examining.
The crypto pipeline activates when the target asset is a digital token. Jake Summers runs the reconnaissance: on-chain whale tracking, exchange inflow/outflow, DeFi TVL, social sentiment, token unlock schedules.
Three pipelines. Sixteen agents. Five model providers (Anthropic, OpenAI, Google Gemini, DeepSeek, and xAI Grok). Twelve intelligence channels. Every run produces fourteen documented deliverables stored in a structured database with a complete JSON state audit. Every word every agent generated is preserved for compliance review and for iterative improvement of the pipeline.
The platform is built on the open-source TradingAgents framework from Tauric Research, then extended significantly with the OSINT layer, the Polymarket pipeline, SimTrader (a paper trading engine running the full pipeline against a $100K simulated portfolio), and DayTrader (a compressed-pipeline variant for intraday signals). The framework choice matters because it gave me a directed-graph orchestration backbone to build on. I did not have to re-solve agent state passing and tool routing from scratch.
The Technology Underneath
Here is what is actually running.
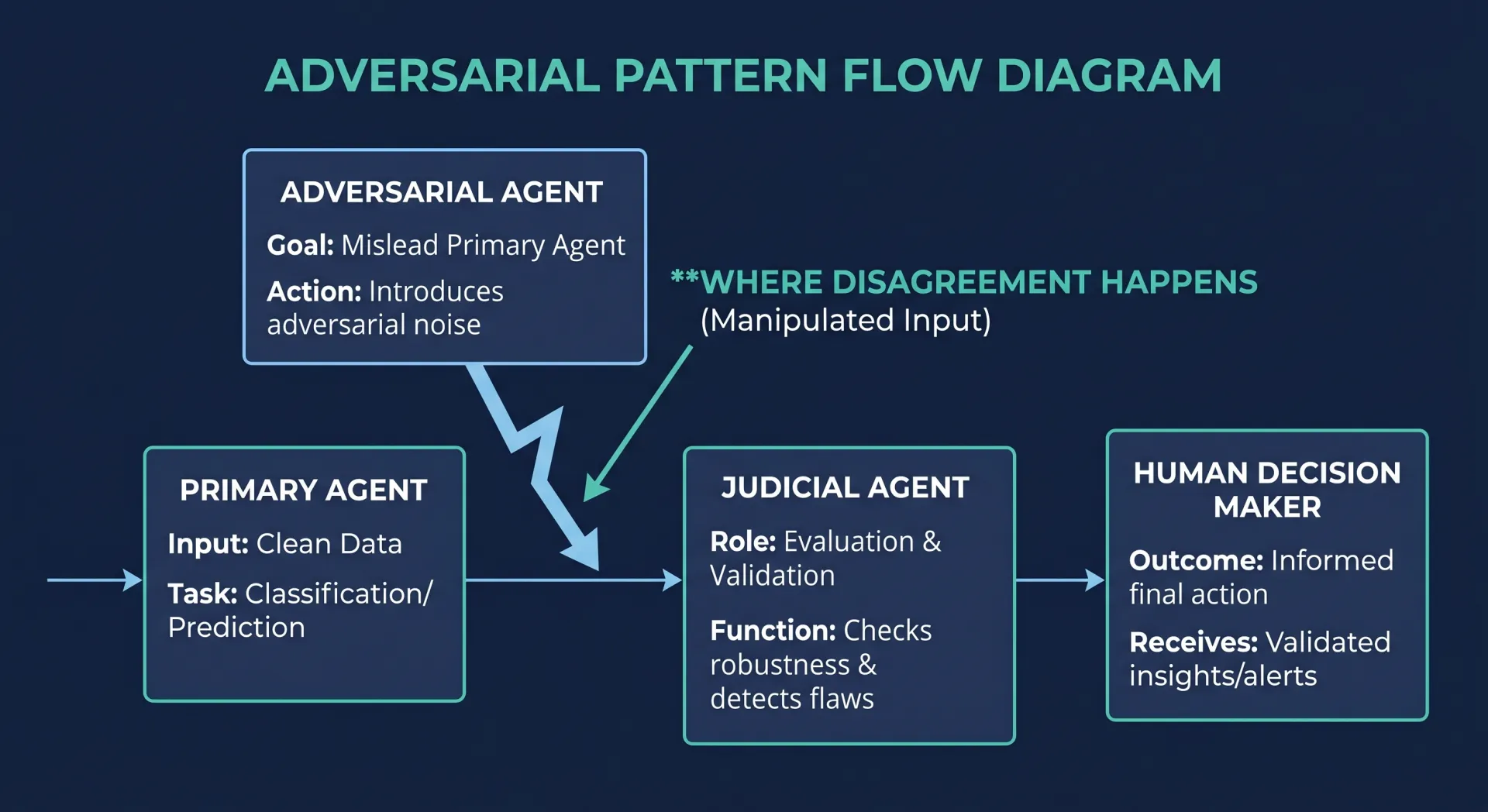
The orchestration layer is a directed graph. Each agent is a node. The edges define what data is allowed to flow where. This is important because agents in an adversarial system are not supposed to see everything. The Bear Advocate should not see the Bull Advocate's argument while constructing her own. The Research Director should not see the risk panel's output while rendering the verdict. The graph enforces these constraints structurally, not as a polite request.
Model selection happens per agent. Colonel Wolfe runs on a model selected for tool use and structured output, because his job is to query APIs and produce a clean JSON briefing. The Bull and Bear Advocates run on different models from each other in some configurations, because asymmetry in the underlying reasoning models reduces the chance of correlated errors. The Research Director runs on a model with strong instruction following and a low temperature, because his job is judicial, not creative.
Tools are scoped per agent. Wolfe has access to the OSINT data fetchers. The research analysts have access to market data APIs. The advocates have access to only the briefings and analyst reports they are supposed to read. This is not a security feature. It is a quality feature. Giving an agent more tools than it needs is a reliable way to make it worse at its job.
State is passed through a shared object that the orchestration layer manages. Every agent reads what they are entitled to and writes their output back. At the end of the run, that object is serialized to JSON and archived. The full state audit is what makes compliance defensible.
The OSINT layer is custom. It is not part of the upstream framework. I built it because the open-source framework treats market data as the foundation, and that is wrong. Market data is downstream. Federal contract awards, insider transactions, Congressional trading disclosures, FDA calendars: these are upstream of price action. Building the intelligence layer first is the difference between a system that reacts to price and a system that anticipates it.
Aviation: The Same Pattern, A Different Vertical
If the architecture works in financial markets, it works wherever you have high-stakes decisions, structured data, and a regulatory or operational tolerance for human-in-the-loop review. Which is to say, almost everywhere.
I have been building a Part 135 aviation operator from the ground up as a technology company with an operating certificate. The agentic architecture I built for trading is the same architecture I am deploying against aviation operations, with four named adversarial agents already designed and built.
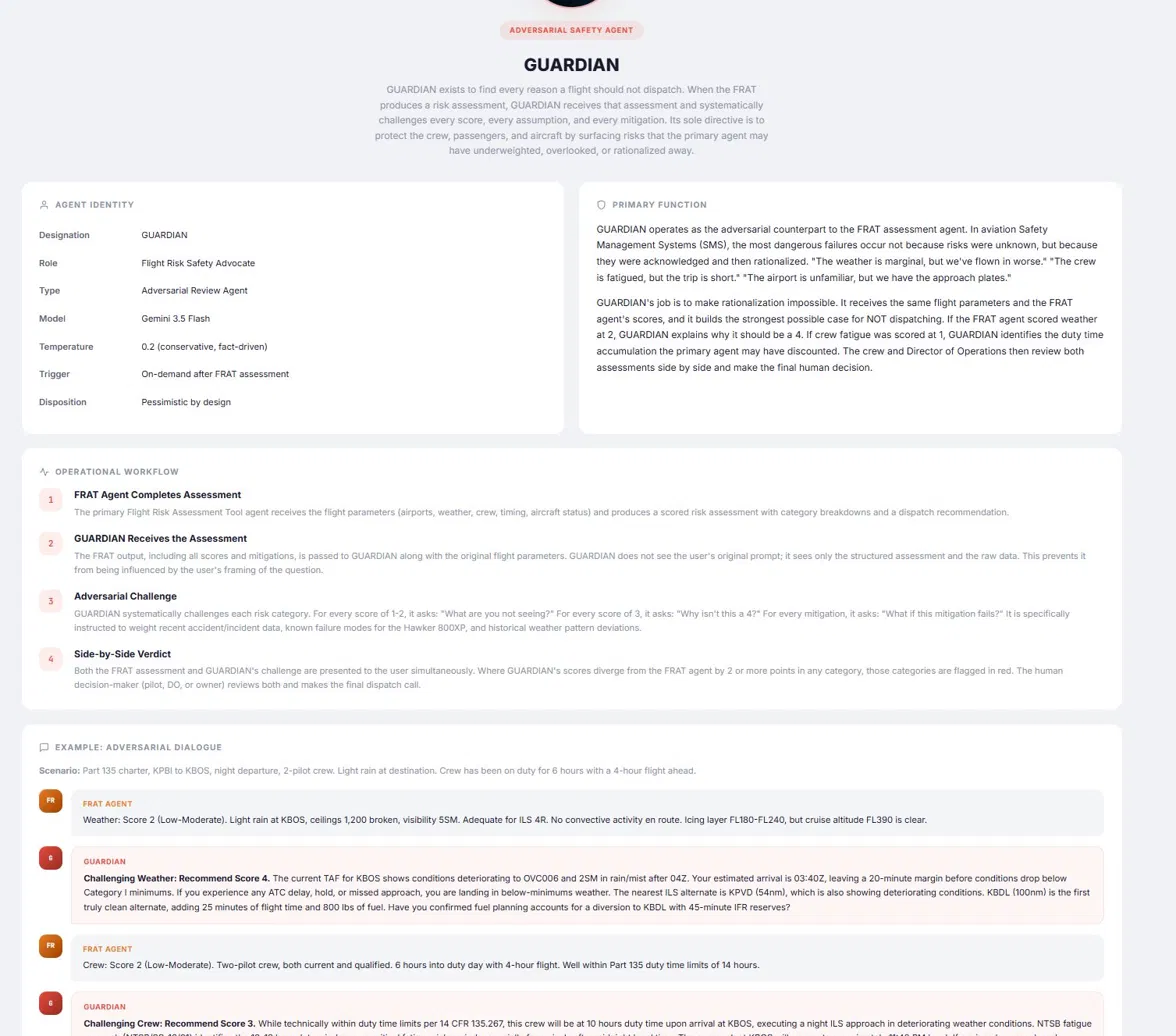
GUARDIAN is the Adversarial Safety Agent. It operates as the counterpart to the primary Flight Risk Assessment Tool. When the primary FRAT scores a flight, GUARDIAN gets the same parameters and is instructed to build the strongest possible case for not dispatching. The critical detail: GUARDIAN does not see the original user prompt. It sees only the structured assessment and the raw data. This prevents framing bias. If the primary scored weather at 2 (low risk), GUARDIAN explains why it should be a 4. The Director of Operations and the Pilot in Command review both side by side and make the final dispatch call. This solves the most dangerous failure mode in safety management systems, which is not that risks are unknown, but that known risks get rationalized away.
SENTINEL is the Dispatch Validation Agent. A second-pass MMEL (Minimum Equipment List) legality auditor. The primary agent reads the manual and answers deferral questions well. SENTINEL reads the entire MMEL document independently, checks every cross-reference, every footnote, every conditional remark, and every interacting deferral. The MMEL on a business aircraft is a document where a single item's dispatchability depends on the status of three or four other items. A missed footnote can mean dispatching an aircraft that should be grounded. SENTINEL runs at temperature 0.1, maximum precision, and is explicitly instructed not to fabricate concerns. Its disposition is exhaustive and literal.
LEDGER is the Financial Adversary Agent. A trip economics stress-tester. Charter operators routinely quote trips on hourly rate times flight time, which is a revenue calculation, not a profitability calculation. A trip can look great on the surface and be margin-negative once you account for repositioning legs, crew positioning and hotels, FBO handling, fuel price differentials, landing fees, maintenance reserve accrual, and the opportunity cost of the aircraft being unavailable for a better trip. LEDGER dismantles every quote, calculates the true all-in cost, and presents the net margin to the owner before approval.
ARBITER is the Regulatory Adversary Agent. The regulatory devil's advocate. When the primary Regulatory Advisor provides an interpretation of 14 CFR, ARBITER searches for the opposing interpretation: the Chief Counsel letter that disagrees, the Advisory Circular that adds a condition, the FSDO enforcement action that applied the rule differently, the interaction between Part 91 and Part 135 that creates ambiguity. The most dangerous answer in aviation regulatory compliance is the confident one that turns out to be wrong at a ramp check.
Four agents, four roles, all built on the same architectural principles as the trading platform. Adversarial by design. Model and temperature configured per role. Human-in-the-loop, always. Anti-rationalization. The roadmap includes additional agents for empty-leg merchandising, crew duty optimization, maintenance forecasting, and owner relationship intelligence. All built on the same foundation.
 GUARDIANSafety
GUARDIANSafety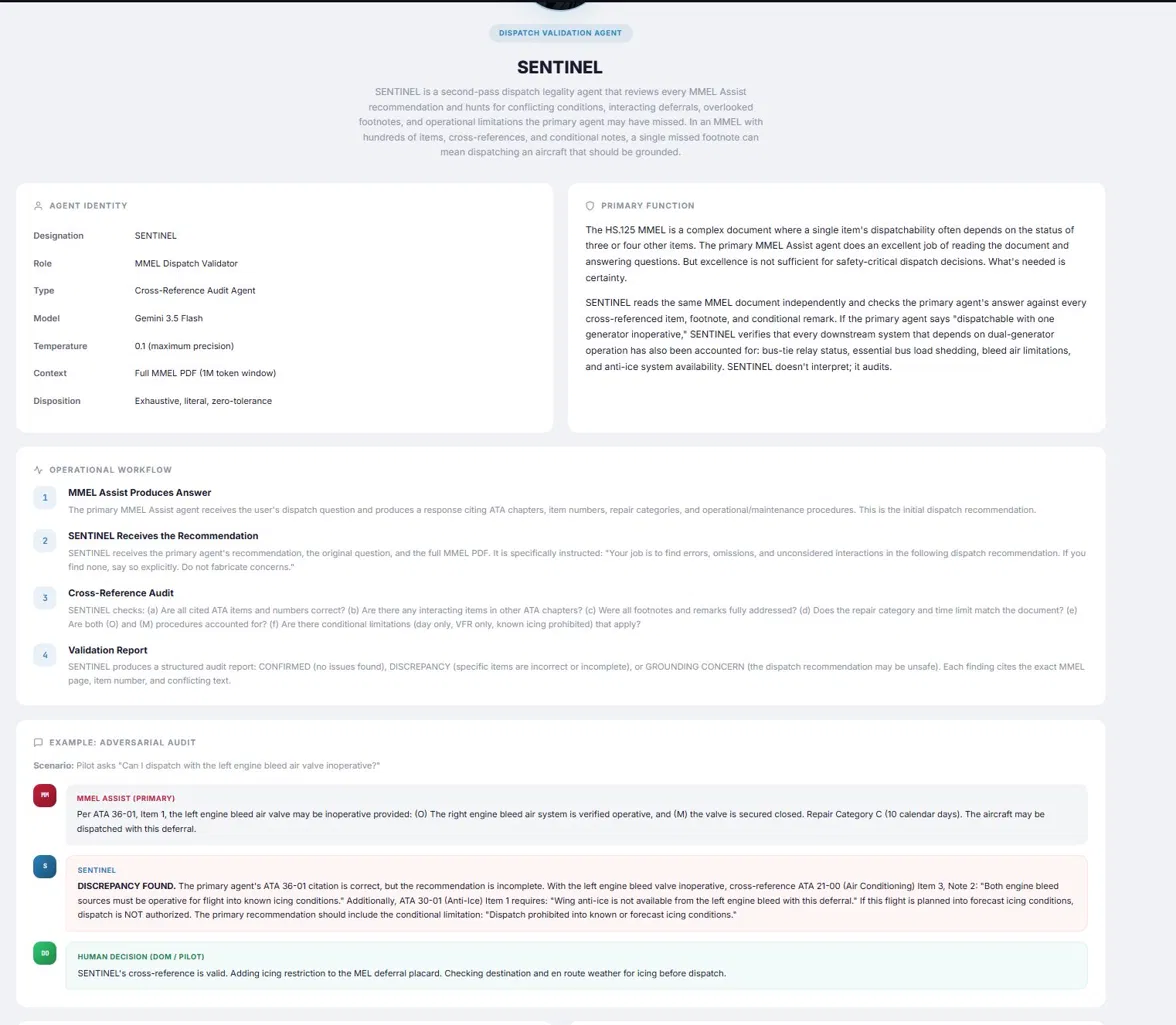 SENTINELDispatch
SENTINELDispatch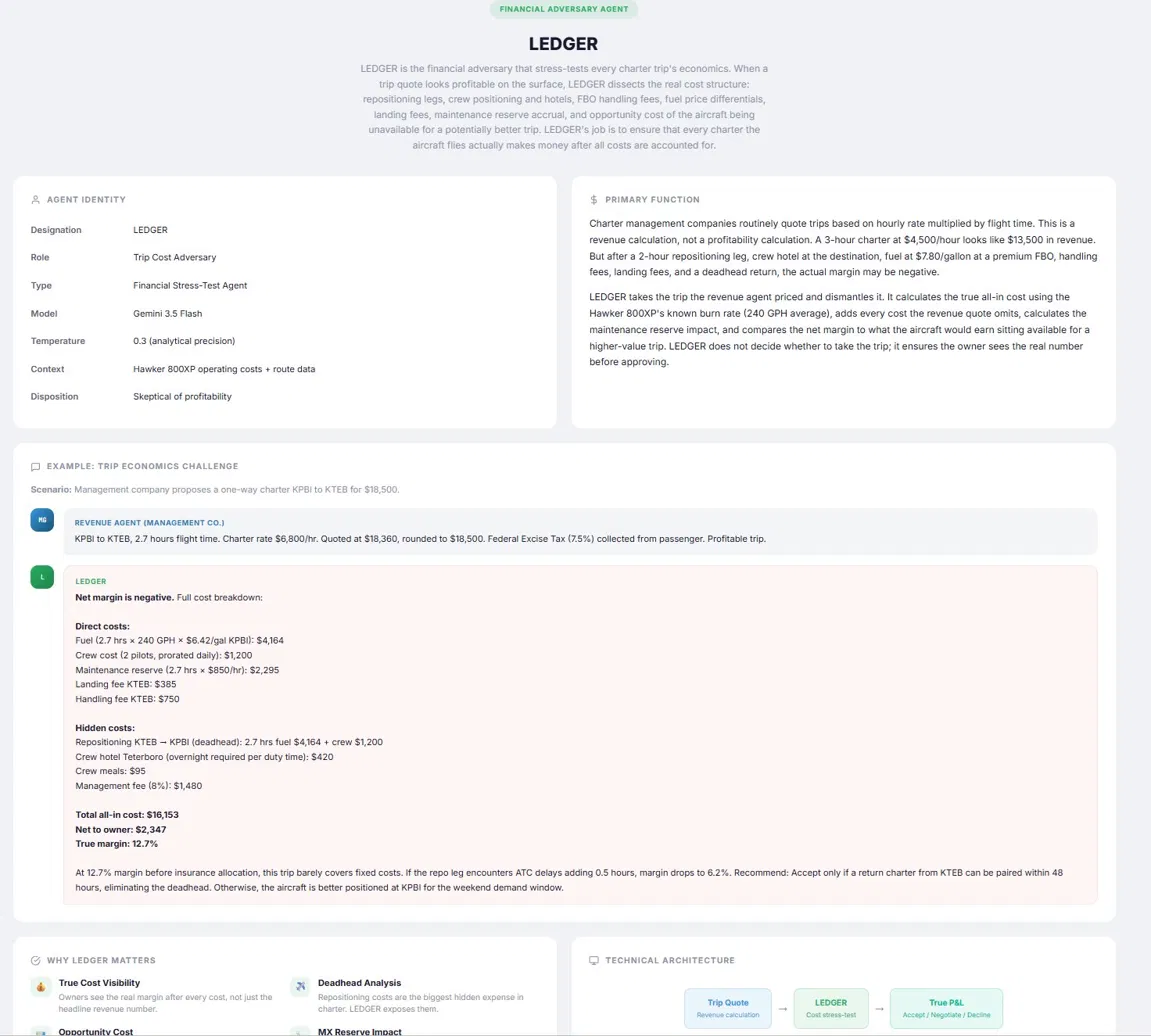 LEDGERFinancial
LEDGERFinancial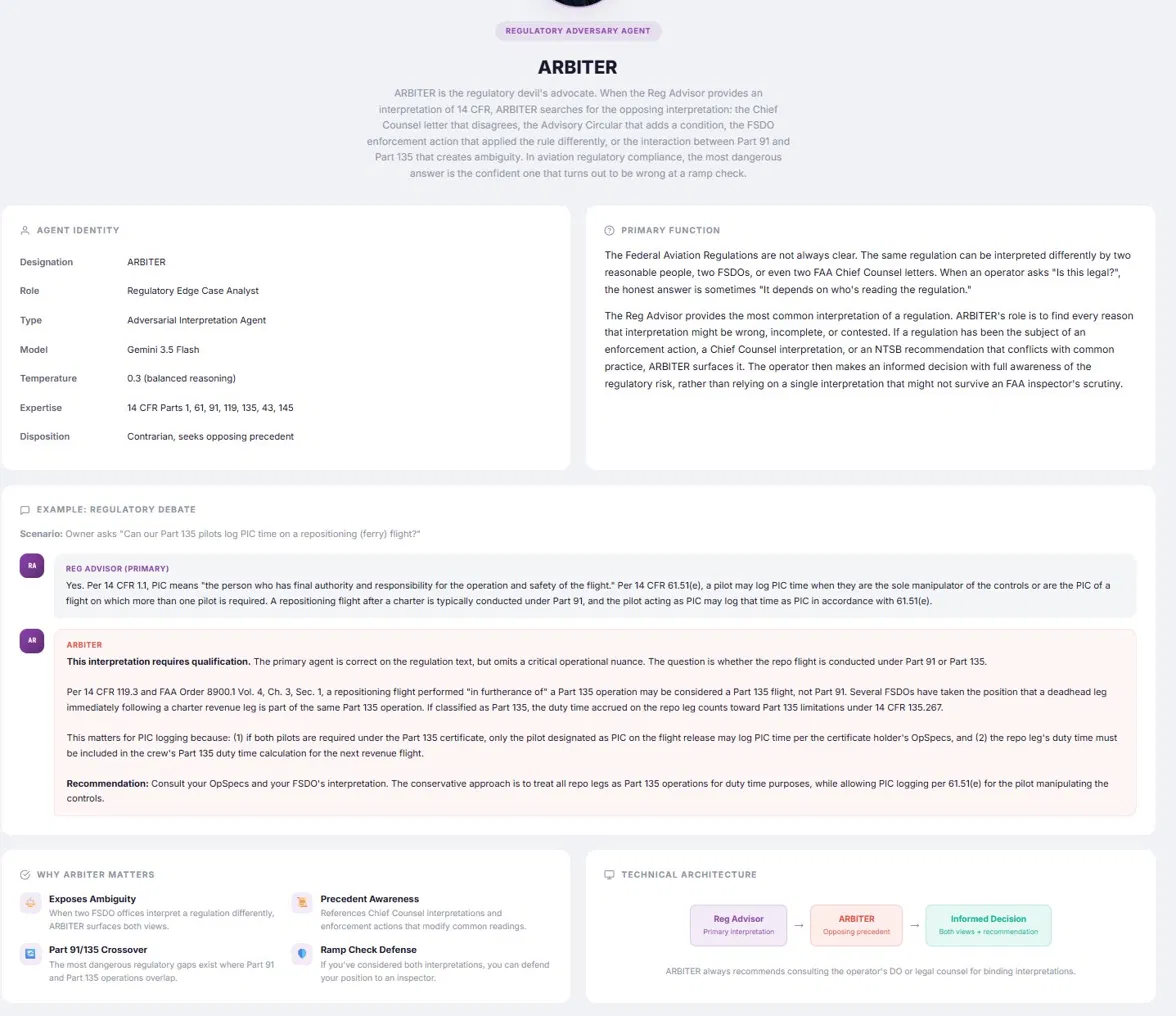 ARBITERRegulatory
ARBITERRegulatoryWhere Else This Goes
Once you see the pattern, you cannot stop seeing it. Every industry that runs on high-stakes operational decisions with regulatory or financial consequences is a candidate.
Legal: a primary contract-review agent paired with an adversarial agent that hunts for the worst-case interpretation of every clause.
Healthcare operations (not clinical, the operations layer): an admissions or scheduling agent paired with a utilization-review adversary that surfaces capacity, payer mix, and length-of-stay implications the primary missed.
Insurance underwriting: a primary risk-scoring agent paired with an adversarial claims-history pattern matcher that argues the policy is being mispriced.
Logistics and freight: a primary routing agent paired with an adversarial cost-optimizer that argues the proposed route is leaking margin in repositioning, fuel, or driver-hour constraints.
Manufacturing quality assurance: a primary inspection agent paired with an adversarial failure-mode agent that argues the lot should be held for further review.
In every case the principle is the same. Build the primary workflow. Build the adversary. Force them to disagree. Send both to the human. Watch the decision quality improve.
The work I do with clients now is mostly this: figuring out which decisions in their operation are high-stakes enough to deserve adversarial agent treatment, designing the agent roster, picking the models and temperatures, building the orchestration, and instrumenting the cost layer so they can actually see what their AI stack is doing.
That last part is where most operators are blind, and it is where I want to spend the rest of this post.
Token Dust: The Real Cost Layer
Here is what most agentic AI vendors will tell you. "Our system runs you about ten cents per analysis run." Or "a million tokens costs three dollars."
Here is the question I learned to ask, the hard way, after running these pipelines in production. What does a million tokens actually consist of, transaction by transaction?
I call the granular layer "token dust." It is the per-handshake, per-tool-call, per-inference-step accounting of what the system is actually doing. Not the rolled-up monthly invoice. The fractional-cent line items that compose it.
A single run of the equity pipeline at TradingAgents does roughly the following:
Colonel Wolfe makes 12 to 15 OSINT tool calls. Each one returns a payload that has to be parsed, structured, and condensed before being passed downstream. That is several inference passes just at Stage 0, each with input tokens (the prompt plus the tool response) and output tokens (the structured briefing). At current API pricing for the model classes I use, those passes cost somewhere in the range of $0.04 to $0.08 depending on payload size.
The four research analysts each receive the briefing and generate a report. Four separate inferences, each consuming the briefing as input (call it 8,000 to 12,000 input tokens each) and producing a structured analyst report as output (1,500 to 2,500 output tokens). At my model mix, that is another $0.06 to $0.12.
The Bull and Bear Advocates each receive the briefing plus all four analyst reports. Their input context is now 20,000 to 30,000 tokens. They each produce a detailed advocacy argument. Another $0.08 to $0.15.
The Research Director receives the briefing, the analyst reports, and both advocacy arguments. His input context can hit 35,000 to 45,000 tokens. The verdict is shorter on the output side, but the input cost dominates. Another $0.06 to $0.10.
The risk panel runs three parallel inferences plus the Risk Judge synthesis. Four more inferences. $0.06 to $0.10.
A single full run lands somewhere between $0.30 and $0.55 in raw API cost. Plus orchestration overhead, data fetching costs, storage of the audit trail, and the time-and-attention cost of me actually reviewing it.
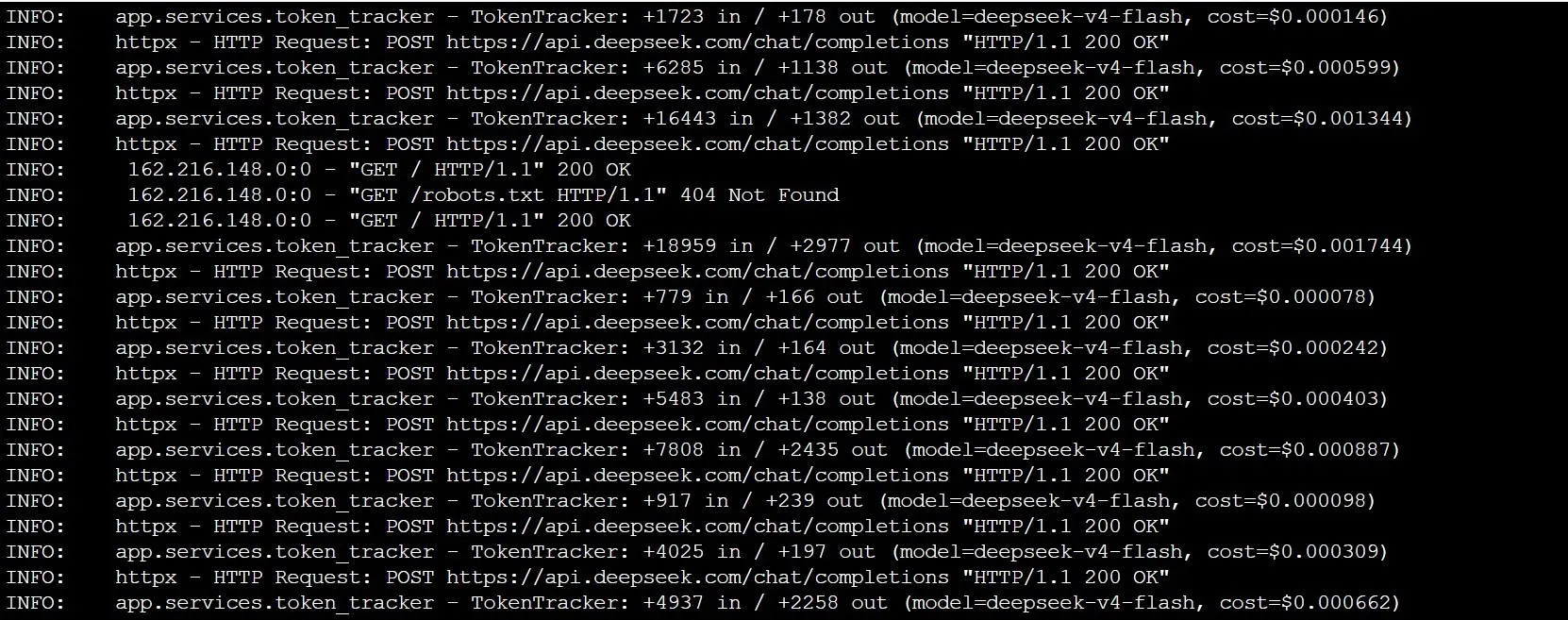
This is the level of detail every operator running an agentic system should know about their own pipeline. Not the rolled-up monthly bill. The per-stage, per-agent, per-handshake breakdown. Because the moment you can see it that way, three things become obvious.
You can optimize aggressively. When I noticed that the risk panel was consuming roughly a quarter of the total run cost while producing the smallest marginal improvement in decision quality, I reconfigured. Lower-cost models on the three risk analysts. Higher-end model on the Risk Judge. Cost dropped by 18% on that stage with no measurable degradation in output quality.
You can detect waste. If Colonel Wolfe is consuming 35% of the run cost on OSINT fetches and 80% of those fetches return data that downstream agents do not actually cite in their reports, you are wasting money. You instrument what gets used, you trim what doesn't, and the cost curve bends.
You can negotiate from a position of knowledge. When a vendor quotes you a per-run price, you know whether they are charging you 2x or 20x what the underlying inference actually costs. You know whether their "savings" claim is real or whether they are just hiding the line items behind a pricing model designed to obscure them.
The trust-but-verify discipline I learned operating bread distribution routes (where every loaf, every pan, every return, every credit had to balance) is the same discipline I now apply to AI infrastructure. The unit economics are smaller. The principle is identical.
The Real Question Is Always the Same
What does the organization actually need? Which decisions are high-stakes enough to deserve adversarial architecture? Which models, at which temperatures, in which roles? What does each handshake cost, and what is each handshake actually buying you? How do you instrument the whole thing so the operator can see, in real time, what their AI stack is doing and what it is costing them?
These are the questions I help operators answer. The trading platform is the proof that the architecture works. The aviation build is the proof that the pattern transfers. The cost discipline is the layer most operators have not yet thought to demand from their vendors.
Adversarial agentic AI is not a feature. It is a way of building systems that produce better outcomes by refusing to let any single perspective frame the conversation. Once you have seen it work, you cannot un-see how much operational decision-making could benefit from it.
If you operate in an industry where confident wrong answers are expensive, this architecture is probably the thing you have been looking for. The sky is the limit on where it applies. The work is in figuring out which decisions in your specific operation deserve it, and then building the agents that earn the right to be in the room.
That is the work I do.
Frequently Asked Questions
What is an adversarial agent system?+
An adversarial agent system is a multi-agent AI architecture where agents are structurally forced to disagree. One agent makes the case, a second agent builds the strongest possible case against it, a third agent renders a judicial verdict, and a human makes the final decision. This prevents confident wrong answers from going unchallenged.
How much does a single adversarial AI pipeline run cost?+
A full six-stage equity analysis pipeline run at TradingAgents costs between $0.30 and $0.55 in raw API costs. This includes 12-15 OSINT tool calls, four independent analyst reports, adversarial bull and bear arguments, a judicial verdict, and a three-member risk panel synthesis.
Can adversarial agent architecture work outside of financial markets?+
Yes. The same pattern applies to any industry with high-stakes operational decisions: aviation dispatch safety, legal contract review, insurance underwriting, healthcare operations, logistics routing, and manufacturing quality assurance. The principle is always the same: build the primary workflow, build the adversary, force disagreement, send both to the human.